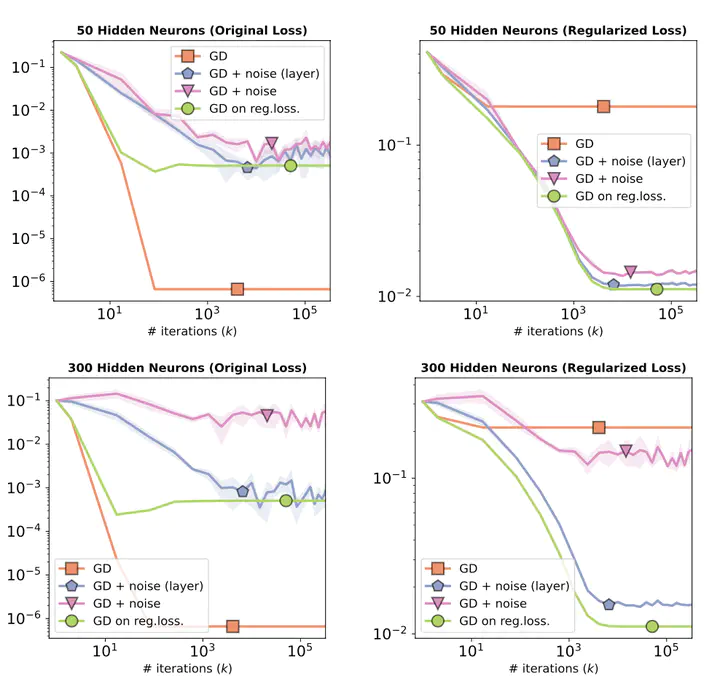
 MLP with 1 hidden layer and linear activations on synthetic data. Both injecting noise layer-wise and to all weights lead to minimization of the regularized loss.
MLP with 1 hidden layer and linear activations on synthetic data. Both injecting noise layer-wise and to all weights lead to minimization of the regularized loss.
Abstract
Injecting noise within gradient descent has several desirable features. In this paper, we explore noise injection before computing a gradient step, which is known to have smoothing and regularizing properties. We show that small perturbations induce explicit regularization for simple finite-dimensional models based on the l1-norm, group l1-norms, or nuclear norms. When applied to overparametrized neural networks with large widths, we show that the same perturbations do not work due to variance explosion resulting from overparametrization. However, we also show that independent layer wise perturbations allow to avoid the exploding variance term, and explicit regularizers can then be obtained. We empirically show that the small perturbations lead to better generalization performance than vanilla (stochastic) gradient descent training, with minor adjustments to the training procedure.